안녕하세요, 구독자님!
8월이 시작되면서 더위와 함께 학문의 열기도 뜨거워지고 있습니다. 빅데이터 러닝센터에서도 빅트리 여러분들의 학구열을 만족시키기 위한 다양한 교육을 준비하겠습니다. :)
이번호에서 다룰 내용을 살펴보겠습니다.
- 센터장님의 기고글
지난호 1편에 이어 2편을 준비했습니다. 높은 퀄리티의 생성형 AI 지식을 쌓아보시기 바랍니다.
- e-튜터 강사 모집
e-튜터 서비스를 시작합니다. 온라인크리에이터로 활동을 해보세요
- 8월 추천 교육
이달의 주목할 만한 교육을 강조하며, 이를 통해 여러분의 데이터 분석 역량을 한층 더 강화할 수 있습니다.
여러분의 학습과 성장을 지원하기 위해 정성껏 준비한 이번 8월호에 많은 기대 부탁드립니다.
|
|
인공지능 기술의 발전(2) – 벡터공간모델과 생성형 AI / By. 정성원 센터장
✔️ 인공지능 기술의 도약T: ChatGP의 등장
2022년 11월 30일, 세상을 깜짝 놀라게 한 AI 서비스인 "ChatGPT"가 출시되었습니다. 이 서비스는 출시 40일 만에 글로벌 일일 이용자 수가 1,000만 명을 넘었습니다. Instagram이 1,000만 명을 돌파하는 데 325일이 걸렸고, 넷플릭스는 3.5년이 걸린 것에 비하면 ChatGPT의 인기가 얼마나 대단한지 쉽게 알 수 있습니다.
|
 |
✔️ 자연어처리의 발전: 인간과 컴퓨터의 소통
ChatGPT는 미국의 OpenAI가 만든 LLM(Large Language Model) 기반의 대화형 AI 서비스입니다. 한번이라도 ChatGPT를 사용해 본 사람은 그 자연스러운 대화에 놀라움을 금치 못합니다. 컴퓨터 프로그램이 어떻게 이렇게 자연스러운 대화를 할 수 있을까? 어떻게 인간의 언어를 이렇게 잘 이해하는 것일까?
✔️ 인간과 컴퓨터의 소통: 자연어처리(NLP) 기술
인간은 컴퓨터를 발명하고 프로그래밍 언어를 만들어 컴퓨터와 소통해 왔습니다. Assembly Language에서 COBOL, Fortran, Pascal, C 등을 거쳐 최신 Python에 이르기까지 프로그래밍 언어는 세대를 거치면서 인간이 이해하고 사용하기 쉬워졌습니다. 하지만 인간은 여전히 프로그래밍 언어보다는 자연어를 사용하여 컴퓨터와 소통하기를 원합니다. 자연어로 컴퓨터와 소통하는 기술을 연구하는 분야가 자연어처리(NLP)입니다. 자연어 처리 기술에는 자연어 분석, 자연어 이해, 자연어 생성 등이 있습니다. 자연어 이해는 컴퓨터가 자연어로 주어진 입력에 따라 동작하게 하는 기술이며, 자연어 생성은 그림, 동영상, 표의 내용을 사람이 이해할 수 있는 자연어로 변환하는 기술입니다.
✔️ 벡터 공간 모델의 탄생과 발전
"까마귀 날자 ( ) 떨어진다"라는 문장을 접한 사람은 자연스럽게 ( )안의 단어가 "배"라는 것을 알 수 있습니다. 인간은 오랜 기간 동안 언어를 사용하면서 단어의 뜻과 문장의 뜻을 학습하여 이해합니다. 그리고 본인이 이해한 단어와 문장을 조합하여 자신의 의사를 표현합니다. 이렇게 언어는 많이 사용하면 할수록 더 자연스럽고 능숙해집니다.
벡터 공간 모델(Vector Space Models)은 단어를 벡터화하여 다차원의 벡터 공간에 위치시키는 방법으로, 의미가 비슷한 단어들이 서로 가까운 곳에 위치하도록 합니다. 많은 문서 집합(Corpus)에서 단어들을 분리하고 특정 단어들이 어떤 단어들과 자주 같이 자주 사용되는지를 근거로 다차원 공간에 위치시키고 좌표를 저장합니다.
|
 |
|
✔️ NNLM의 제안과 한계
캐나다 몬트리올대학교의 Yoshua Bengio 교수는 2003년에 딥러닝 알고리즘 기반의 단어 벡터 공간 모델링 방법의 하나인 NNLM(Neural Network Language Model)을 제안했습니다. NNLM은 연속적인 단어에서 이전 단어를 입력하여 현재 단어를 예측하는 방법인데, 단어를 의미 있는 벡터로 임베딩하는 데는 성공적이었지만 트레이닝 세트의 단어 수에 비례하여 엄청난 수의 파라미터를 추정해야 하는 계산 복잡성으로 인해 트레이닝이 매우 느리다는 단점을 갖고 있어 실용화되지 못했습니다.
✔️ Word2Vec의 혁신
구글은 2013년에 NNLM의 문제점인 학습 파라미터의 수를 획기적으로 줄인 벡터 공간 모델링 방법인 Word2Vec을 발표했습니다. Word2Vec은 특정 단어에 대해 근처에 출현하는 다른 단어들을 관련 단어로 딥러닝 모델을 학습시키는 방식입니다. Word2Vec은 주어진 단어로 주변에 들어갈 단어를 맞추는 Skip-Gram 모델과 주변 단어들로 빈자리에 들어갈 단어를 맞추는 CBOW(Continuous Bag-Of-Words) 모델로 나누어 볼 수 있습니다. 예를 들어 "집"이라는 단어를 기준으로 "사람", "마당", "주소"와 같은 단어들을 예측하는 것이 Skip-Gram 모델 방식이고, "사람", "마당", "주소"와 같은 단어를 기준으로 "집"이라는 단어를 예측하는 것이 CBOW 모델 방식입니다. Skip-Gram 모델은 정확도가 NNLM의 2배 이상이고 성능은 7배 이상입니다. Word2Vec 모델 학습 결과로 생성된 단어들의 좌표 벡터는 다차원 벡터 공간상의 단어들 위치를 표현하는 정보가 됩니다. 벡터로 표현된 단어들은 수학적 연산이 가능해져,
"King - Man + Woman = Queen" 과 같은 연산도 가능합니다. 생성된 단어 벡터값은 트레이닝하는 문장의 수에 의해 그 정확도가 결정됩니다.
✔️ Doc2Vec와 Transformer의 등장
구글은 2014년에 단어 수준 표현에 중점을 둔 Word2Vec 모델을 더 발전시킨 Doc2Vec 모델을 발표했고, 이어서 2017년 6월에는 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 딥러닝 모델인 Transformer 모델을 발표했습니다. Transformer 모델의 변환기는 전체 단어를 한꺼번에 처리하며, 주변 단어를 기반으로 각 단어의 컨텍스트 정보를 인코딩합니다. 변환기의 attention 메커니즘은 입력 시퀀스 간의 연관성을 파악하고 단어 간의 관계를 효과적으로 캡처할 수 있습니다.
✔️ GPT 모델의 진화
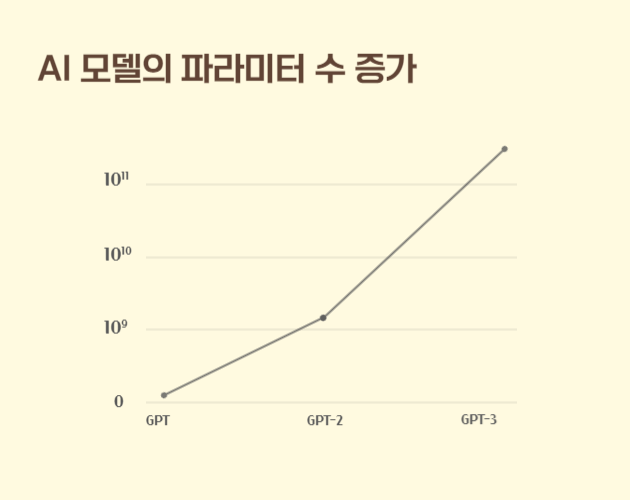
2018년 6월에 Generative Pre-trained Transformer(GPT)가 처음 등장했습니다. Generative Pre-trained Transformer는 생성형 사전학습된 Transformer 모델을 의미합니다. GPT는 대규모 언어 모델링을 통해 사전학습된 모델을 만들고 이 모델을 자연어처리의 각 과업에 맞는 작은 데이터셋으로 학습하는 파인튜닝 과정을 거치게 함으로써 우수한 성능을 나타낼 수 있게 되었습니다. Transformer 모델은 파라미터 수가 클수록 성능이 더 좋아지는데, GPT는 파라미터 수가 1억 7천만 개였지만, 2019년 2월에 발표된 GPT-2는 15억 개로 늘어났고, 2020년 6월에 발표된 GPT-3는 파라미터 수가 무려 1,750억 개로 늘어났습니다.
|
 |
✔️ 다양한 AI 모델의 발전
2021년 1월에는 이미지를 텍스트와 같이 학습한 모델인 CLIP과 DALL-E가 발표되었습니다. CLIP은 이미지를 분류하는 모델이고, DALL-E는 주어진 텍스트로부터 이미지를 생성하는 모델입니다. 또한 2021년 8월에는 프로그래밍 코드 생성을 위한 모델인 Codex가 발표되었습니다. 2022년 1월에는 간단한 자연어 지시만으로도 사용자가 요청한 대로 결과물을 생성하는 Instruction fine-tuning 기능을 적용한 InstructGPT 모델이 발표되었습니다.
✔️ GPT-3.5와 ChatGPT의 출현
2022년 3월에 발표된 GPT-3.5는 GPT-3에 프로그래밍 코드 데이터와 Instruction fine-tuning 기능을 추가한 버전입니다. 이어서 2022년 11월에 등장한 ChatGPT는 AI의 대중화를 이끈 모델로 GPT-3.5를 파인튜닝한 것입니다. ChatGPT 모델의 학습 방식을 살펴보면, 첫 번째 단계에서는 지시 프롬프트와 데이터셋으로 이루어진 Demonstration data를 넣어줍니다. 여기서 라벨러는 지시 프롬프트에 적합하다고 여겨지는 행동을 라벨링하는데, 이렇게 모아진 데이터셋은 SFT(Supervised Fine Tuning) 모델 학습을 통해 GPT-3.5를 파인튜닝하는 데 활용됩니다. 다음 단계에서는 유저의 선호도에 대한 보상 모델(Reward model, RM)을 활용해 ChatGPT를 강화학습(Reinforcement learning, RL)으로 업데이트합니다. 이러한 방식을 통해 ChatGPT는 보다 다양하고 유연한 대화를 제공할 수 있게 되었습니다.
✔️ GPT-4와 GPT-4o: 인공지능의 미래
2023년 3월에 발표된 GPT-4는 텍스트와 시각적 입력을 모두 생성할 수 있는 점이 특징입니다. 즉, GPT-4는 이미지와 그에 대한 질문을 분석하여 답변할 수 있습니다. GPT-4는 특정 이미지에 대한 자세한 보고서를 생성해야 하는 경우 매우 유용하게 사용될 수 있습니다. 2024년 5월에는 GPT-4의 업그레이드 버전인 GPT-4o가 발표되었습니다. 이는 핸드폰 카메라를 통해 사람의 표정을 읽을 수 있고, 사람과 대화하는 것과 유사한 속도로 대화를 할 수 있습니다. 지능은 GPT-4와 비슷한 수준이지만 응답 속도는 GPT-4보다 2배 이상 빠릅니다. 또한 영어 외의 언어 능력도 개선되어 직접 한국어로 질문해봤을 때 답변의 퀄리티가 많이 향상되었습니다. (完)
|
|
🔥지난 Datasolution Day: AI Discovery 2024에서 정성원 센터장님의 기조연설에서 발표하신 인공지능 기술의 발전과 활용분야 영상입니다.
|
|
빅데이터 러닝센터 정성원 센터장님이 진행하는 강의 목록
(과정명을 누르면 소개페이지로 넘어갑니다.)
|
|
📣 전문 지식으로 수익을 창출하세요! e-튜터 모집 중!
|
|
빅트리 여러분의 도메인 지식과 경험을 활용하여 데이터 분석 강의를 개설할 e-튜터를 모집합니다. 다양한 분야의 실무자와 전문가 분들을 대상으로 하는 e-튜터에 많은 관심과 참여를 부탁드립니다.
e-튜터 소개
e-튜터는 자신의 도메인 지식과 통계 역량을 결합하여 온라인 교육 콘텐츠를 기획하고 강의를 진행하는 역할을 합니다. 이는 여러분이 쌓아온 전문 지식을 통해 추가 수입을 창출할 수 있는 훌륭한 기회입니다.
지원자격
- 다양한 분야의 실무자 및 전문가
- 자신의 도메인 지식을 활용하여 추가 수입을 창출하고자 하는 분
빅데이터 러닝센터와 함께 새로운 도전을 시작하세요! 여러분의 많은 관심과 참여를 기대합니다.
|
'Chat GPT를 활용한 데이터분석'
일시: 8/5~6 (월~화) 10:00 ~ 17:00
Chat GPT를 활용한 데이터분석 과정이 많은 관심 속에 3번째 오픈을 진행합니다! 이 과정에서는 Chat GPT를 통해 간편하고 효율적으로 데이터를 분석하는 방법을 학습합니다. Chat GPT를 직접 실습하며 새롭고 유익한 스킬들을 익혀보세요!
'SPSS 중급통계분석1: 분산분석'
일시: 8/19~20(월~화) 10:00 ~ 17:00
SPSS 중급통계분석1: 분산분석 과정을 통해 통계분석뿐만 아니라 실증데이터 분석에 활용 가능한 다양한 분석기법을 습득할 수 있습니다. 주로 실험데이터를 다루거나 집단간의 차이비교 분석을 하시는 분들께 적극 추천드립니다!
'KCI, SCI, SSCI 논문게재를 위한 효과적인투고요령 및 해결책'
일시: 8/30(금) 10:00 ~ 17:00
KCI, SCI, SSCI 논문게재를 위한 효과적인 투고요령 및 해결책 과정에서는 논문 게재의 실질적인 가이드를 제공합니다! 다양한 논문 게재 방법을 학습하고, 실습 및 질의응답을 통해 직접적인 솔루션을 얻어갈 수 있습니다.
|





 로그인을 해주세요
로그인을 해주세요









